Tic Tac Toe
Reinforcement LearningHow it works
The game is the implementation of Tic Tac Toe where the opponent is a Q-Network agent. A Q-Network is a type of neural network that outputs the expected future reward (or ~prob of winning) for each action. This is trained using the reinforcement learning technique Deep Q-Network (DQN).
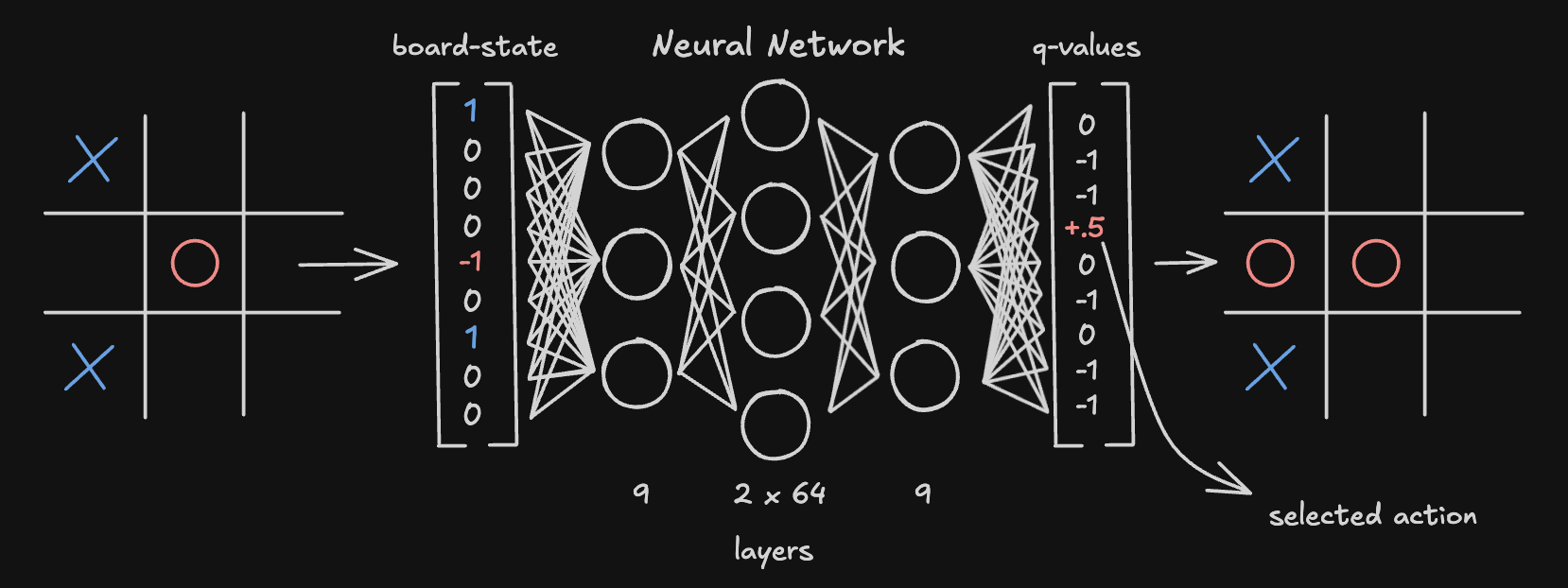
The Image shows that the q-values are not exactly the probability of winning, but the expected reward from taking that action. The selected action is the one with the highest q-value.
Training Process
The underlying model is a Feed-Forward Neural Network (MLP) with the following structure:
- Input: 9 neurons (one for each board cell)
- Hidden Layers: 2 layers of 64 neurons each (ReLU activation)
- Output: 9 neurons (representing q-values for each position)
The agent was trained by playing thousands of episodes (games) on multiple hours of CPU time against a random opponent first and then against itself. It utilizes an experience replay buffer to break correlations between consecutive learning steps and a target network to stabilize the learning of Q-values.
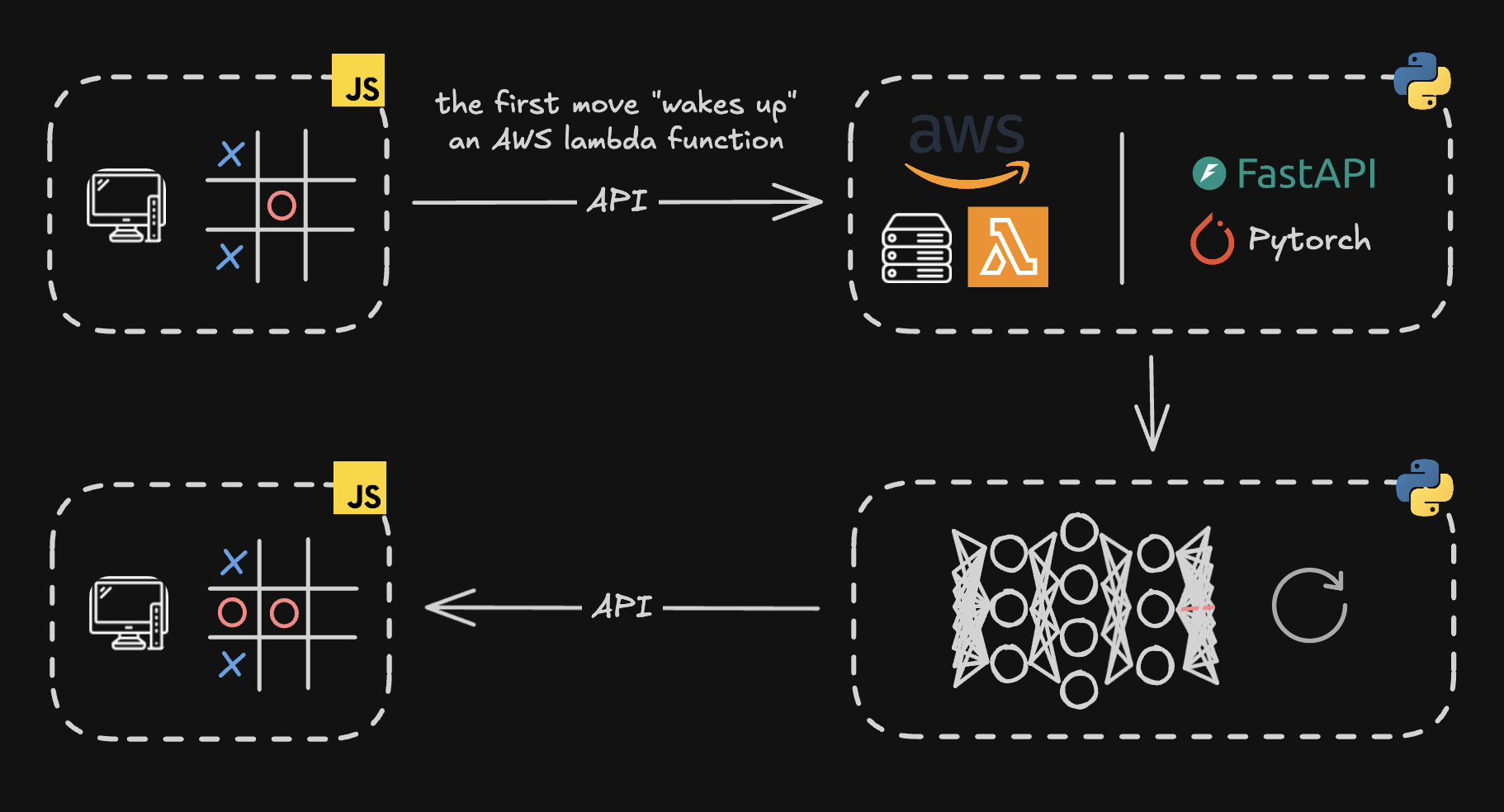
Backend Implementation
The backend running the neural network is decoupled from the website. For each user action, the backend is invoked via an API call to an external endpoint hosted on AWS. The backend is deployed as an AWS Lambda function running a FastAPI application packaged as an ECR container image.
References & Code
The complete training code, including the environment setup and hyperparameters, is available on GitHub:
For a deeper theoretical understanding of the methods used:
- Human-level control through deep reinforcement learning (Mnih et al., 2015) - The seminal paper on DQN.
- Reinforcement Learning: An Introduction (Sutton & Barto) - Chapters 6 & 16 covering Temporal-Difference Learning.